


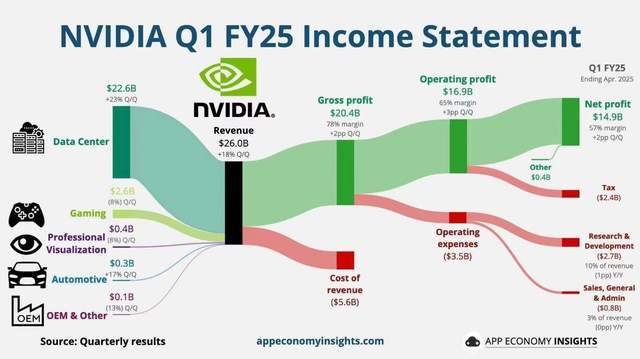
英伟达Q1收入260亿美元,同比增长262%,市值直冲3万亿美元——这点燃了全球AI和半导体市场。交银国际的评价是:“虽然不乏竞争者,但英伟达数据中心的高增长,将维持至少2年”。
英伟达市值持续超越三万亿背后,是市场对其技术路线、商业模式、市场前景的认可。凯发K8一触即发而在中国这样一个技术迅猛发展、市场前景广阔的新兴市场,是否会再催生一个如英伟达的高成长性芯片公司?
寻找“中国英伟达”,就是要寻找与英伟达底层商业逻辑最为接近的公司。在中国众多优秀芯片公司中,我们不得不把目光落在一家仅用100天就成长为独角兽,在国产AI芯片市场不可忽视的GPU公司——摩尔线程。
OpenAI提出7万亿芯片计划,宁可与全球AI产业链“为敌”;苹果将在6月公布AI全新战略;英伟达在Hopper之后的下一代芯片Blackwell已提速量产,今年Q3就将放量出货,年出货量可达150万片以上。
英伟达不打算做英特尔那样的牙膏厂,Blackwell的再下一代芯片Rubin,更是将换代间隔从2年缩减到1年1代,甚至制程都要重新规划以绕开台积电产能的限制,因为所有科技公司都对先进算力趋之若鹜,没人愿意等上12个月才能拿到H100。
这还不包括大模型公司和科技巨头在软件、数据、算法层面的变化,性能突破、兼并整合、再融资也是热闹非凡。
在令人兴奋的喧嚣声中,英伟以崛起的数据中心业务,在24个月内从30亿美元/季度暴增到226亿美元/季度,Google、META、亚马逊等巨头为其贡献了80%的营收。算力需求激增、数据中心功耗暴涨,Scaling Law之下的算力需求似乎是无上限的。
从业务板块来看,英伟达数据中心单季收入高达惊人的226亿美元,环比增长23%(上一季度数字已很惊人),是其超级增长引擎;游戏业务收入则为26亿美元,环比增长8%,是稳定的现金奶牛;视觉成像和自动驾驶等则稳步增长。
而在中国市场,“百模大战”之下的中国机会更令人兴奋。由于众所周知的原因,英伟达的中国市占率步步收紧,中国芯片正迎来崛起的窗口期。据The Information报道,中国监管层要求科技公司增加对国产AI芯片的采购量,这将对国产算力产生较大利好。阿里、腾讯、百度、字节对高性能算力趋之若鹜,也希望尽快实现国产化替代。
对技术自主可控的需求在AI时代显得尤为重要。中国这样一个有着巨大市场和潜力的国家,在以金融、电信、电力、能源等行业为开端的技术自主可控试点中更是创造出了千亿级市场。AI时代,算力是基础,国产芯片将成为刚需。据中国移动透露,预计2024年AI智算采购规模将达到17EFLOPS(FP16)及以上,占公司总体算力规模比例达到40%左右。据业内人士表示,等到中移动下一轮集采时,国产算力占比就有望超过50%。中国市场的巨大机会正在反哺优秀的中国芯片企业。
那么在中国,凯发K8一触即发哪家公司能像英伟达一样,以通用GPU技术横扫数据中心、游戏、视觉成像等赛道呢?纵观国内k8凯发,从统一的系统架构、视觉+AI智算卡的产品布局、具备千卡以上大规模集群部署能力、以及团队基因和国际化视野这几个角度来看,与英伟达最为神似的是GPU公司摩尔线程。
摩尔线程创始人张建中曾是英伟达全球副总裁、中国区总经理,核心技术团队大多来自英伟达等芯片巨头,拥有国内领先的全栈自研实力。从诞生之日起,摩尔线程就选择“全功能GPU”这一难度最大、潜力最高的技术路线。基于摩尔线程自研MUSA架构,摩尔线程GPU内置AI加速、视频编解码、3D图形渲染、科学计算四大计算引擎,可以满足大模型、AIGC、数字孪生、物理仿真和图形渲染等多个场景需求,是国内唯一可以在功能上与英伟达对标的公司,覆盖的场景和潜在市场也是如此。
在硬件方面,摩尔线程是国内唯一一次性设计点亮,并实现量产和商业化的通用型全功能GPU公司。苏堤、春晓、曲院三颗全功能GPU芯片均在创纪录的短时间内,实现了高性能设计和量产。更不用说,摩尔线程是目前唯一一家量产并在京东公开售产图形显卡的公司。摩尔线程是有技术底蕴的,旗舰显卡MTT S80现已支持大量DirectX11游戏,硬件性能更是达到了RTX3060水准。不止图形渲染,摩尔线程在AI领域已经悄悄建立起了从芯片到板卡,从服务器到集群的AI智算产品线。
软件方面,基于MUSA架构,摩尔线程打造了完整的软件栈,包括统一的编程模型、软件运行库、驱动程序框架、指令集架构和芯片架构等。摩尔线年就推出MUSA Toolkit 1.0软件工具包,包含MUSA驱动、运行时库、编译器、AI加速库、数学库、通信库等,可充分发挥摩尔线程GPU的计算能力。与此同时,摩尔线程还推出了代码移植工具musify,可以很好兼容CUDA,零成本完成CUDA代码自动移植,之后用户短时间内即可完成热点分析和针对性优化,大大缩短迁移优化的周期,让开发者省时省力省心。
摩尔线程还拥有国内首屈一指的显卡驱动团队,以月为单位提升S系列显卡的性能,对Direct X12的支持指日可待。从2022年开始,摩尔线程还布局了自己的云计算团队,仅用1年多时间就推出了软硬一体的夸娥智算中心全栈解决方案,其分布式并行计算、集群可靠性、高性能通信的能力都是有先进的软件能力支撑。

数据中心无疑是目前英伟达的核心增长引擎,千卡、万卡集群是高营收的基石。据财报显示,英伟达数据中心Q1营收226亿美元,环比增长23%,单季度收入甚至高于2021年全年。
SORA、Llama3、GPT5这几个今年爆火的大模型,制造了天量的算力需求,达到了万卡级别,比如META推出两个24576块H100 GPU的超大集群,对应下一代的AGI训练。
对国产算力来说,必须具备千卡集群的能力,这是对标英伟达的入场券。目前摩尔线程就是能建设全国产千卡集群的唯二公司。
在AI大模型腾飞之初的2022年,摩尔线程就瞄准了国内AI算力市场,洞察大模型算力需求,从智算卡开始,逐渐布局服务器、大规模集群,最终在2023年推出夸娥千卡智算集群——以全功能GPU为底座,软硬一体化的全栈解决方案,包括了大模型平台、KUAE集群管理平台,以及计算、网络、存储等基础设施。
夸娥千卡智算集群具备8大核心能力,在软硬件上全面对标英伟达。依次来说,夸娥的核心优势是模型覆盖、CUDA兼容、断点续训、分布式训练、推理加速、高性能通信、高性能存储和集群可靠性,确保了高兼容性、高稳定性和高算力利用率。
夸娥解决了国产算力商业化的2个核心技术痛点。首先,集群规模上到千卡之后,有效算力利用率会大幅下降。对此,摩尔线程从算法、通信、调度、硬件资源配置等多个方面协同优化,可实现高达91%的千卡集群性能扩展系数。其次是大规模集群的故障率问题,摩尔线程的应对措施是系统级的集群监控、故障诊断和恢复能力,在千卡集群上达到了7天连续无故障训练和分钟级的故障恢复。
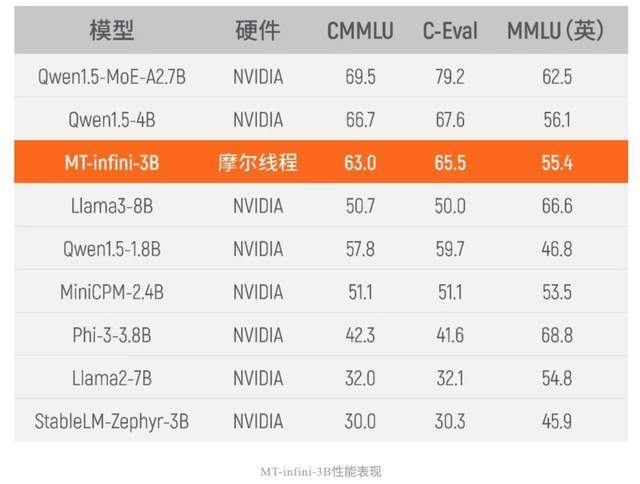
那么夸娥的实测效果如何呢?日前,国内领先的AI算力中间层公司无问芯穹,已用夸娥千卡智算集群成功进行了的3B规模大模型实训。无问芯穹的目标是实现多种大模型算法在多元芯片上的高效、统一部署,融合“M种模型”和“N种芯片”。这次MT-infini-3B实训模型训练总用时13.2天,集群训练稳定性达到100%,千卡训练和单机相比扩展效率超过90%。实训出来的MT-infini-3B性能在同规模模型中跻身前列,在C-Eval,MMLU,CMMLU等3个测试集上均实现性能领先。
此外,摩尔线程还与多个国产大模型完成了训练、推理的兼容适配,合作伙伴包括了滴普科技、实在智能、羽人科技等多家知名公司。
夸娥千卡集群的落地正在提速。自从2023年11月发布以来,摩尔线个千卡以上级别的智算中心,分别位于北京亦庄、北京密云和江苏南京,并正在快速迈向万卡集群时代。
数据中心和千卡万卡集群的落地,既是对标英伟达的入场券,又是国产AI芯片公司竞逐万亿蓝海市场的增长引擎。结合中国AI算力千载难逢的市场机遇,以摩尔线程为代表的国产GPU公司,有着不可限量的商业机会。返回搜狐,查看更多
-
友情链接 :
- k8凯发天生赢家·中国·一触即发
联系凯发k8
 手机:15817255623
手机:15817255623
 邮箱:admin@zghxzs.com
邮箱:admin@zghxzs.com
 传真:+15817255623
传真:+15817255623
 地址:江苏省常州市新北区创业路16号粤海工业园3C
地址:江苏省常州市新北区创业路16号粤海工业园3C